
Swaroop Nath
Pre-Doctoral Researcher @ Google DeepMind
Experience
Pre-Doctoral Researcher
Google DeepMind
July 2024 - Present
AI/ML Research Intern
May 2023 - July 2023
Education
MS by Research, CSE
Indian Institute of Technology, Bombay
Aug 2021 - June 2024
About Me
Hi! I am a Pre-Doctoral Researcher in Google DeepMind India. Here I work with the amazing folks in the Machine Learning and Optimization team, led by Dr. Prateek Jain. My work mostly revolves around efficiency — where I initially dabbled with Efficient Attention, and eventually moved to Efficient Reasoning.
Prior to this, I graduated as an MS by Research scholar from the CFILT Lab, IIT Bombay. I was fortunate enough to be advised by Dr. Pushpak Bhattacharyya (God rest his soul) and Dr. Harshad Khadilkar. My Thesis was recognized with the Winifred B. Fernandes Research Excellence Award
. My works have been featured in A* NLP conferences — EMNLP and ACL.
News
-
➤
Attending ACL 2024 in Thailand to present our paper:
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
.August 2024
-
➤
Received the
Winifred B. Fernandes Research Excellence Award
for my MS Thesis at IIT Bombay.June 2024
-
➤
Graduated from IIT Bombay with an MS by Research in Computer Science & Engineering.
June 2024
-
➤
Selected to join Google DeepMind as a Pre-Doctoral Researcher from a competitive pool of applicants.
February 2024
-
➤
Best talk award for
Efficient Reward Modelling in RLHF
at RISC'24, CSE@IIT-Bombay.January 2024
-
➤
Attended EMNLP 2023 in Singapore to present our paper:
Reinforcement Replaces Supervision: Query focused Summarization using Deep Reinforcement Learning
.December 2023
-
➤
Delivered a part of a tutorial on Vision-Language Models at ICON 2023.
December 2023
-
➤
Delivered a tutorial on RLHF and Alignment Research at Qualcomm.
August 2023
-
➤
Led IIT Bombay teams to Silver and Bronze Medals in Inter IIT Tech Meet.
Dec 2022 & Jan 2023
Publications & Pre-Prints (* = Equal Contribution)
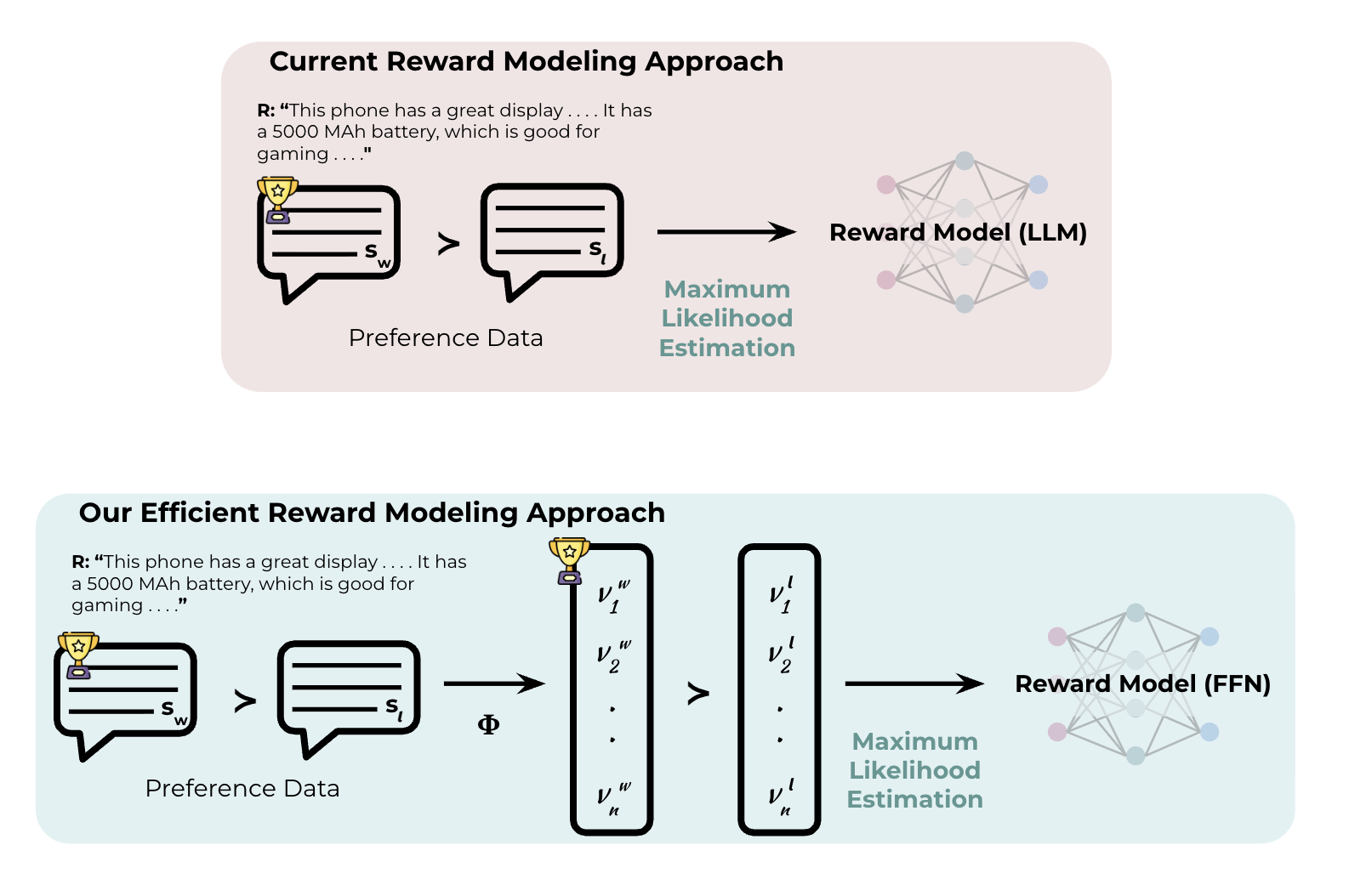
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF
Swaroop Nath*, Tejpalsingh Siledar*, Pushpak Bhattacharyya, et al.
arXiv Preprint
This research explores a novel reward modeling approach for Reinforcement Learning from Human Feedback (RLHF) that significantly reduces the need for human preference data by leveraging domain knowledge, demonstrated in the context of e-commerce opinion summarization.
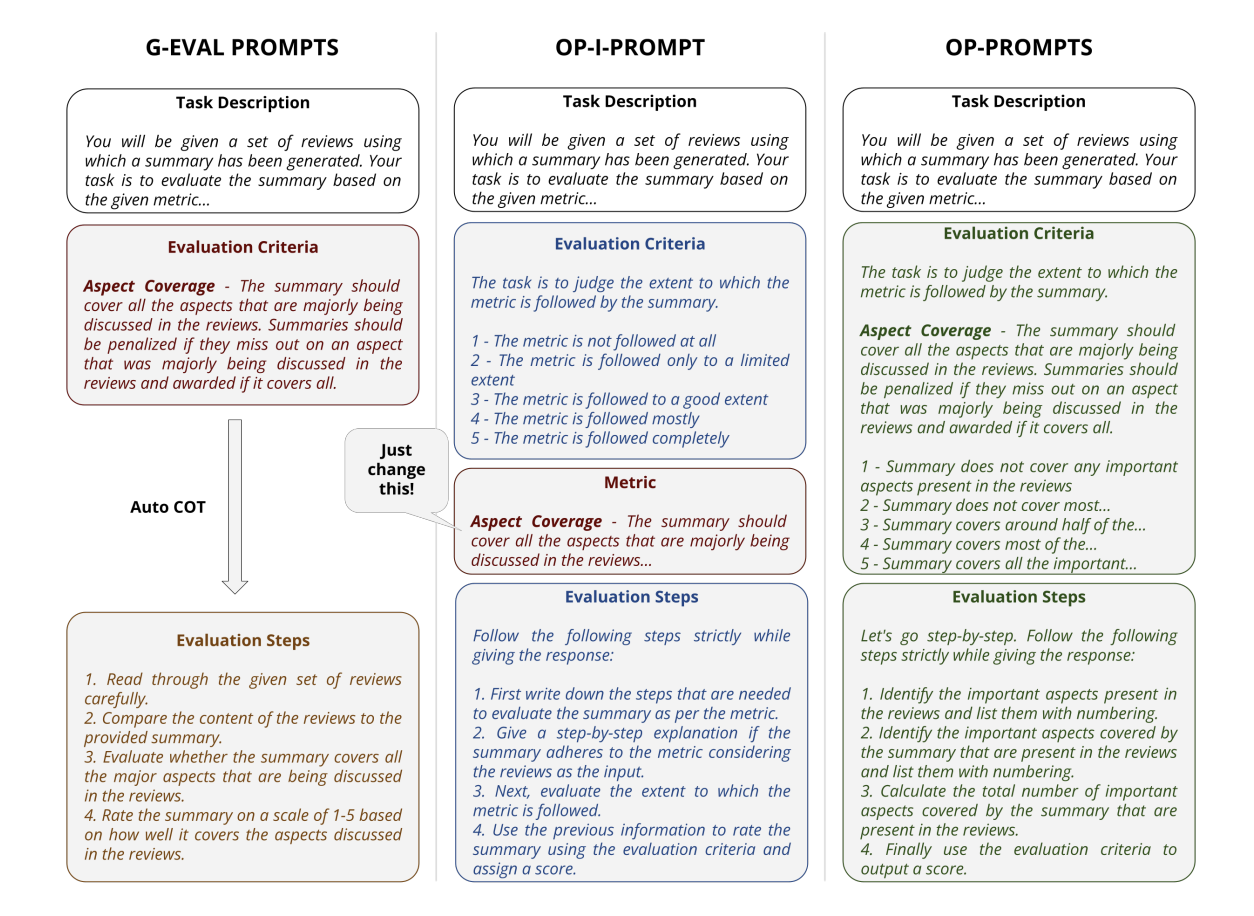
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
Swaroop Nath*, Tejpalsingh Siledar*, Pushpak Bhattacharyya, et al.
ACL 2024
This work introduces SUMMEVAL-OP, a benchmark dataset for evaluating opinion summaries, and proposes two novel prompting strategies (OP-I-PROMPT and OP-PROMPTS) that significantly improve the correlation of LLM-based evaluations with human judgments, especially for open-source models.
Transformers are Expressive, But Are They Expressive Enough for Regression?
Swaroop Nath, Harshad Khadilkar, and Pushpak Bhattacharyya
arXiv Preprint
This work investigates the theoretical and empirical limitations of Transformer models in approximating smooth functions, a fundamental aspect of regression tasks. The findings suggest inherent constraints on their expressivity in this domain.
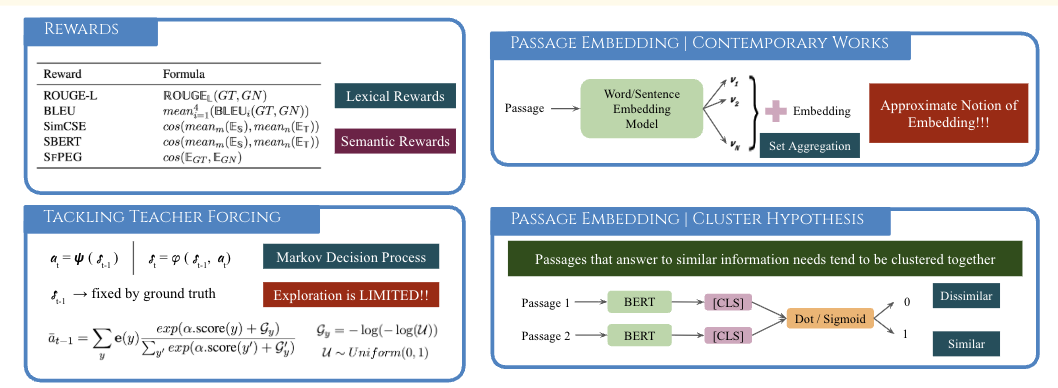
Reinforcement Replaces Supervision: Query focused Summarization using Deep Reinforcement Learning
Swaroop Nath, Pushpak Bhattacharyya, and Harshad Khadilcar
EMNLP 2023
This paper proposes a novel reinforcement learning (RL) algorithm for query-focused summarization (QfS), achieving significant improvements over state-of-the-art supervised methods. The approach also introduces a new passage embedding scheme to create a more effective reward function for training.